How Oracle is Bridging the Gap Between JSON Schema and Relational Databases
As modern multi-model databases increasingly support JSON, it's time to explore what role JSON schema will play. In this post, we'll dive into the newly developed "Database Vocabulary", a proposed extension to the official JSON schema specification, developed by Oracle (with inputs from the MySQL and PostgreSQL teams). This vocabulary addresses key database tasks, including validation, type coercion/casting, and metadata preservation, making it easier to manage JSON in databases effectively and bridging the gap with existing relational data. Regardless of whether you are a JSON developer or a relational model developer, you'll learn something reading this post!
Oracle Database 23ai fully implements this new vocabulary, and we'll describe not only the concepts but we'll also see real-world examples of JSON schema validation in action and how to describe database objects in JSON schema.
JSON Data Guide
With Oracle Database 12cR2 (2017), we've introduced the concept of a JSON data guide; that lets you discover information about the structure and content of existing JSON documents stored in JSON columns inside the database.
Let's look at the following example which creates a table blog_posts with a column data of type JSON and inserts one JSON document:
1create table blog_posts (
2 data json -- BINARY JSON
3);
4
5insert into blog_posts( data ) values (
6 json {
7 'title': 'New Blog Post',
8 'content': 'This is the content of the blog post...',
9 'publishedDate': '2023-08-25T15:00:00Z',
10 'author': {
11 'username': 'authoruser',
12 'email': 'author@example.com'
13 },
14 'tags': ['Technology', 'Programming']
15 }
16);
17commit;
18We can query the table and retrieve JSON values using the SQL dot notation to navigate the JSON document hierarchy. Attributes within the JSON document can simply be referenced by .<attribute name>:
1select -- field names are case sensitive
2 p.data.title,
3 p.data.author.username.string() as username,
4 p.data.tags[1].string() as "array_field[1]"
5 from blog_posts p;
6The item method string() allows explicit casting of the JSON field value. Alongside string() are other casting methods like number(), date(), etc.
However, nothing prevents us from inserting unexpected data!
1insert into blog_posts( data ) values( '{ "garbageDocument":true }' );
2commit;
3
4select data from blog_posts;
5Results:
| DATA |
|---|
| { "title": "New Blog Post", "content": "This is the content of the blog post...", "publishedDate":"2023-08-25T15:00:00Z", "author": { "username":"authoruser", "email":"author@example.com" }, "tags": [ "Technology", "Programming" ] } |
| { "garbageDocument":true } |
This is where, JSON schemas can help, and the JSON_DATAGUIDE() function can generate one from a set of already existing JSON document(s):
1select json_dataguide(
2 data,
3 dbms_json.format_schema,
4 dbms_json.pretty
5 ) as json_schema
6 from blog_posts;
7Results:
We can see that the garbageDocument field was properly detected and added to the set of accepted JSON fields for the JSON schema.
Data Validation
The most obvious use case for JSON schema is JSON data validation. The Oracle Database 23ai brings the new PL/SQL package DBMS_JSON_SCHEMA which can be used to validate JSON schemas and JSON data.
The dbms_json_schema.is_schema_valid() function can tell us if a given JSON schema itself is valid:
1-- Validate the generated JSON schema
2select dbms_json_schema.is_schema_valid(
3 (
4 -- Generate JSON Data Guide/Schema from data column
5 select json_dataguide(
6 data,
7 dbms_json.format_schema,
8 dbms_json.pretty
9 ) as json_schema
10 from blog_posts
11 )
12) = 1 as is_schema_valid;
13Another function dbms_json_schema.validate_report() validates a JSON document against a JSON schema and generates a validation report, including validation errors, if there are any:
1-- Validate current JSON data with a simple JSON schema
2select dbms_json_schema.validate_report(
3 data,
4 json( '{
5 "type": "object",
6 "properties": {
7 "tags": {
8 "type": "array",
9 "items": {
10 "type": "string"
11 }
12 }
13 }
14 }' )
15 ) as report
16from blog_posts;
17Results:
| REPORT |
|---|
| { "valid": true, "errors": [] } |
| { "valid": true, "errors": [] } |
With the simplistic JSON schema, no validation errors are present. Let's use a more complex JSON schema (based on the Blog post example from the JSON schema website itself):
1select dbms_json_schema.validate_report(
2 data,
3 json('{
4 "$id": "https://example.com/blog-post.schema.json",
5 "$schema": "https://json-schema.org/draft/2020-12/schema",
6 "description": "A representation of a blog post",
7 "type": "object",
8 "required": ["title", "content", "author"],
9 "properties": {
10 "title": {
11 "type": "string"
12 },
13 "content": {
14 "type": "string"
15 },
16 "publishedDate": {
17 "type": "string",
18 "format": "date-time"
19 },
20 "author": {
21 "$ref": "https://example.com/user-profile.schema.json"
22 },
23 "tags": {
24 "type": "array",
25 "items": {
26 "type": "string"
27 }
28 }
29 },
30 "$def": {
31 "$id": "https://example.com/user-profile.schema.json",
32 "$schema": "https://json-schema.org/draft/2020-12/schema",
33 "description": "A representation of a user profile",
34 "type": "object",
35 "required": ["username", "email"],
36 "properties": {
37 "username": {
38 "type": "string"
39 },
40 "email": {
41 "type": "string",
42 "format": "email"
43 },
44 "fullName": {
45 "type": "string"
46 },
47 "age": {
48 "type": "integer",
49 "minimum": 0
50 },
51 "location": {
52 "type": "string"
53 },
54 "interests": {
55 "type": "array",
56 "items": {
57 "type": "string"
58 }
59 }
60 }
61 }
62 }')
63) as report
64from blog_posts;
65Results:
| REPORT |
|---|
| { "valid": true, "errors": [] } |
| { "valid": false, "errors": [ { "schemaPath": "$", "instancePath": "$", "code": "JZN-00501", "error": "JSON schema validation failed" }, { "schemaPath": "$.required", "instancePath": "$", "code": "JZN-00515", "error": "required properties not found: 'title', 'content', 'author'" } ] } |
Now we can see that the second JSON document shows several validation errors, namely the missing fields title, content and author.
If you don't want or need to know the validation error details, you may simply use the dbms_json_schema.is_valid() function.
Finally, you can leverage the dbms_json_schema.describe() function to generate JSON schemas from existing relational objects such as tables, views, and JSON Relational Duality Views (more on that later).
1-- Get the JSON schema from a relational table!
2select dbms_json_schema.describe( 'BLOG_POSTS' ) as json_schema;
3Results:
| JSON_SCHEMA |
|---|
| { "title": "BLOG_POSTS", "dbObject": "APIDAYS.BLOG_POSTS", "type": "object", "dbObjectType": "table", "properties": { "DATA": {} } } |
Client-side validation using JSON Schema
Now that we are able to create and retrieve JSON schemas from the database, we may consider the database as a central repository for JSON schemas that can be used by clients (backends and frontends) to validate JSON data.
Below, you can see a quick overview of a demo available in this GitHub repository:
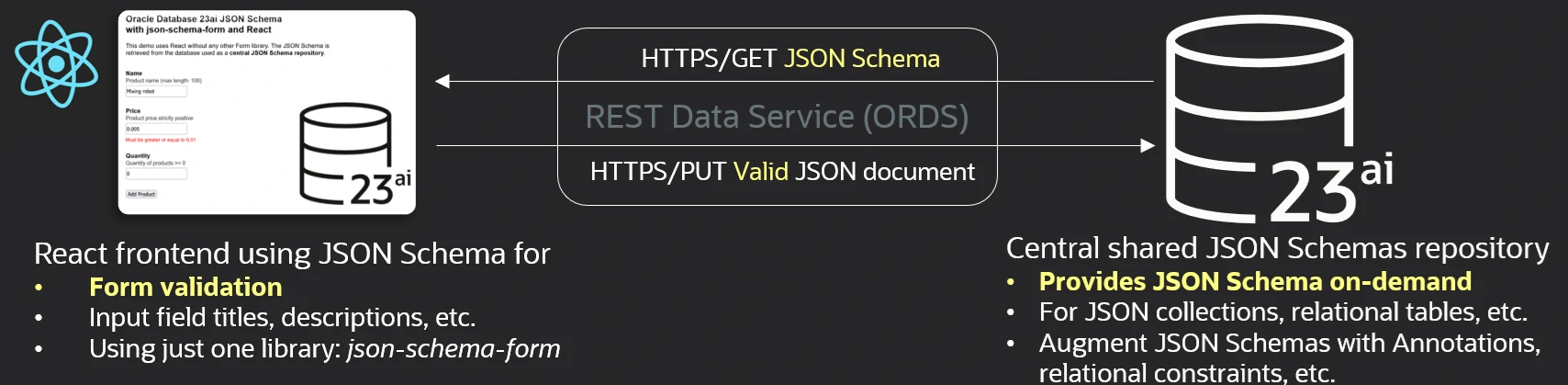
Using Oracle REST Data Services, we can indeed expose a JSON schema to a frontend via REST. Below, we are using the json-schema-form library to build an input form from a JSON schema where title, description, and check constraints are used to define input fields and associated validation rules. Let's drill down into this example:
We'll start by creating a basic relational table that will store products:
1-- drop table if exists products purge;
2
3create table products (
4 name varchar2(100) not null primary key
5 constraint minimal_name_length check (length(name) >= 3),
6 price number not null
7 constraint strictly_positive_price check (price > 0),
8 quantity number not null
9 constraint non_negative_quantity check (quantity >= 0)
10);
11
12insert into products (name, price, quantity)
13values ('Cake mould', 9.99, 15),
14 ('Wooden spatula', 4.99, 42);
15commit;
16This table has 3 columns. Each column has a named check constraint ensuring inserted values are conform with business rules (strictly positive prices, etc.).
If we retrieve the JSON schema corresponding to this relational table using dbms_json_schema.describe(), we'll also get these check constraints translated into the JSON schema format:
1-- JSON Schema of PRODUCTS table
2-- Contains check constraints!
3select dbms_json_schema.describe( 'PRODUCTS' ) as json_schema;
4Results:
One thing we remark is the absence of title and description attributes for our 3 columns but considering JSON schemas are also JSON documents, we may enrich the JSON schema with the missing values.
Database Schema Annotations
Starting with the Oracle Database 23ai, you can leverage Schema Annotations to annotate database objects (columns, tables, views, indexes, etc.).
Consider the following schema annotations:
1ALTER TABLE products MODIFY name ANNOTATIONS (
2 ADD OR REPLACE "title" 'Name',
3 ADD OR REPLACE "description" 'Product name (max length: 100)',
4 ADD OR REPLACE "minLength" '3'
5);
6
7ALTER TABLE products MODIFY price ANNOTATIONS (
8 ADD OR REPLACE "title" 'Price',
9 ADD OR REPLACE "description" 'Product price strictly positive',
10 ADD OR REPLACE "minimum" '0.01'
11);
12
13ALTER TABLE products MODIFY quantity ANNOTATIONS (
14 ADD OR REPLACE "title" 'Quantity',
15 ADD OR REPLACE "description" 'Quantity of products >= 0',
16 ADD OR REPLACE "minimum" '0'
17);
18These schema annotations provide additional information for each relational columns. Note that the minimum and minLength ones are here to work around a current json-schema-form library limitation (hopefully, this open issue will be solved soon).
These annotations are stored inside the database dictionary and can be retrieved via the user_annotations_usage dictionary view:
1-- View annotations
2select column_name, annotation_name, annotation_value
3 from user_annotations_usage
4 where object_name='PRODUCTS'
5 and object_type='TABLE'
6order by 1, 2;
7Results:
| COLUMN_NAME | ANNOTATION_NAME | ANNOTATION_VALUE |
|---|---|---|
| NAME | description | Product name (max length: 100) |
| NAME | minLength | 3 |
| NAME | title | Name |
| PRICE | description | Product price strictly positive |
| PRICE | minimum | 0.01 |
| PRICE | title | Price |
| QUANTITY | description | Quantity of products >= 0 |
| QUANTITY | minimum | 0 |
| QUANTITY | title | Quantity |
To mix both, the table JSON schema with these column level annotations, we can use the following PL/SQL function:
1-- Annotate JSON Schema with column level annotations
2-- p_table_name: the table name to work on
3create or replace function getAnnotatedJSONSchema( p_table_name in varchar2 )
4return json
5as
6 schema clob; -- the original JSON schema
7 l_schema JSON_OBJECT_T; -- the JSON schema as DOM to modify
8 l_properties JSON_OBJECT_T; -- the "properties" JSON object entry of the JSON schema
9 l_keys JSON_KEY_LIST; -- the list of JSON field names of "properties" JSON object
10 l_column JSON_OBJECT_T; -- the JSON object to modify (for each column of the table)
11begin
12 -- get JSON schema of table
13 select json_serialize( dbms_json_schema.describe( p_table_name )
14 returning clob ) into schema;
15
16 -- create a DOM object
17 l_schema := JSON_OBJECT_T.parse( schema );
18 -- access the "properties" JSON schema field that lists all the table columns
19 l_properties := l_schema.get_Object('properties');
20 -- get all the field names of this "properties" DOM: the table columns
21 l_keys := l_properties.get_Keys();
22
23 -- loop over all the columns...
24 for i in 1..l_keys.count loop
25 l_column := l_properties.get_Object( l_keys(i) );
26
27 -- now retrieve from the database dictionary, all the annotations
28 -- associated with this table column
29 for c in (select ANNOTATION_NAME, ANNOTATION_VALUE
30 from user_annotations_usage
31 where object_name=p_table_name
32 and object_type='TABLE'
33 and column_name=l_keys(i))
34 loop
35 -- add each annotation found as a new key/value pair to the JSON schema
36 -- for that table column
37 l_column.put( c.ANNOTATION_NAME, c.ANNOTATION_VALUE );
38 end loop;
39 end loop;
40
41 -- returns the annotated JSON schema
42 return l_schema.to_json;
43end;
44/
45Then one can use the function as below:
1select getAnnotatedJSONSchema( 'PRODUCTS' );
2Results:
GET method
The previous SQL query can then be used as the parameterized template for our REST end point for the GET method:
1-- Run only once:
2BEGIN
3 ORDS.ENABLE_SCHEMA(
4 p_enabled => TRUE,
5 -- database user/schema
6 p_schema => 'APIDAYS',
7 p_url_mapping_type => 'BASE_PATH',
8 p_url_mapping_pattern => 'apidays',
9 p_auto_rest_auth => FALSE);
10
11 ORDS.DEFINE_MODULE(
12 p_module_name => 'apidays',
13 p_base_path => '/schema_repository/',
14 p_items_per_page => 25,
15 p_status => 'PUBLISHED',
16 p_comments => NULL);
17
18 ORDS.DEFINE_TEMPLATE(
19 p_module_name => 'apidays',
20 p_pattern => 'products',
21 p_priority => 0,
22 p_etag_type => 'HASH',
23 p_etag_query => NULL,
24 p_comments => NULL);
25
26 ORDS.DEFINE_HANDLER(
27 p_module_name => 'apidays',
28 p_pattern => 'products',
29 p_method => 'GET',
30 p_source_type => 'json/item',
31 p_mimes_allowed => NULL,
32 p_comments => NULL,
33 p_source =>
34'select getAnnotatedJSONSchema( ''PRODUCTS'' ) as schema');
35
36COMMIT;
37
38END;
39/
40In the GitHub repositoy, you'll find the src/ORDS.js module that demonstrates using this REST method:
1import axios from 'axios';
2
3function ORDS() {}
4
5ORDS.prototype.getSchema = async function() {
6 return await axios.get(
7 'http://localhost/ords/apidays/schema_repository/products',
8 {}
9 )
10 .then( res => res.data.schema )
11 .catch(err => err);
12}
13
14export default new ORDS();
15With all this in place, our React frontend can now create the following form:

Interestingly, whenever you change the schema annotation in the database, it is immediately reflected inside your browser once you refreshed it. You can try with:
1ALTER TABLE products MODIFY name ANNOTATIONS (
2 REPLACE "title" 'Product name'
3);
4JSON Relational Duality View
Once the new product has been validated inside the frontend, it is sent to the database for insertion into the relational table. To ease this process, we'll leverage one of the greatest 23ai new features: JSON Relational Duality View.
This new type of view acts as a gateway between the JSON and relational worlds. Basically, one can insert JSON documents into a JSON relational duality view and the database will automatically map the proper JSON fields to the relational columns. From a retrieval perspective, whenever a JSON relational duality view is queried, a JSON document will be constructed from the underlying relational model at runtime.
Consider this very simple example (not even involving relationships between tables, nor flex fields, etc.):
1-- GraphQL notation (SQL notation also exists)
2create or replace json relational duality view products_dv as
3products @insert {
4 _id: NAME
5 PRICE
6 QUANTITY
7};
8Here we ask the view to accept INSERT SQL statements (via @insert) and remap the JSON _id attribute (mandatory JSON unique key) to the relational column NAME (note that JSON fields are case-sensitive). The other two attributes are automatically mapped because the JSON attributes and relational table column names are the same.
You can find hereunder the JSON schema of this JSON relational duality view:
1-- Get JSON Schema from JSON Relational Duality View
2select dbms_json_schema.describe( 'PRODUCTS_DV' );
3Results:
So now we can run such an INSERT statement:
1-- Insert JSON in a Relational table (Bridging the Gap...)
2-- by using the JSON Relational Duality View
3insert into PRODUCTS_DV(data) values(
4 json_transform( '{
5 "NAME": "Other nice product",
6 "PRICE": 5,
7 "QUANTITY": 10
8 }',
9 RENAME '$.NAME' = '_id'
10 )
11);
12
13commit;
14You will notice that we are using the JSON_TRANSFORM() function to rename the NAME JSON attribute to _id expected by the PRODUCTS_DV JSON relational duality view.
1select * from products_dv;
2select * from products;
3Running the 2 queries above respectively returns the data in JSON format:
| DATA |
|---|
| { "_id": "Cake mould", "PRICE": 9.99, "QUANTITY": 15, "_metadata": { ... } } |
| { "_id": "Wooden spatula", "PRICE": 4.99, "QUANTITY": 42, "_metadata": { ... } } |
| { "_id": "Other nice product", "PRICE": 5, "QUANTITY": 10, "_metadata": { ... } } |
...and relational format:
| NAME | PRICE | QUANTITY |
|---|---|---|
| Cake mould | 9.99 | 15 |
| Wooden spatula | 4.99 | 42 |
| Other nice product | 5 | 10 |
The _metadata object will contain additional information such as an etag that can be used for optimistic concurrency control.
POST method
With the JSON relational duality view in place, we can now implement the REST POST method by adding another ORDS handler:
1BEGIN
2 ORDS.DEFINE_HANDLER(
3 p_module_name => 'apidays',
4 p_pattern => 'products',
5 p_method => 'POST',
6 p_source_type => 'plsql/block',
7 p_mimes_allowed => NULL,
8 p_comments => NULL,
9 p_source =>
10'begin
11 insert into PRODUCTS_DV( data ) values( json_transform(:body_text, RENAME ''$.NAME'' = ''_id'') );
12 commit;
13end;');
14
15COMMIT;
16
17END;
18
19/
20Precheck Check Constraints
With 23ai, a check constraint can now be marked as PRECHECK. Doing so tells the database that a relational check constraint has a corresponding JSON schema constraint that preserves the semantics of the constraint and hence the database doesn't need to verify the check again. An example of a constraint that has no corresponding JSON schema constraint could be a foreign key.
Once a check constraint is marked as PRECHECK, you have the choice whether or not to disable the check constraint on the table as the retrieved JSON schema with dbms_json_schema.describe() will contain the check constraints as well.
We do NOT advise to disable check constraints as it would allow inserting bad data into the relational tables directly. The remark about PRECHECK constraints is here to provide as much information as possible.
1-- Mark check constraints as PRECHECK
2alter table products modify constraint strictly_positive_price precheck;
3alter table products modify constraint non_negative_quantity precheck;
4
5-- Now disable the constraints at the database level
6-- They are checked in the clients
7--
8-- Warning: do that at your own risks!
9alter table products modify constraint strictly_positive_price disable;
10alter table products modify constraint non_negative_quantity disable;
11
12-- Check constraints still present inside the JSON Schema
13select dbms_json_schema.describe( 'PRODUCTS' );
14
15-- but following INSERT will work and insert bad data
16insert into products (name, price, quantity)
17values ('Bad product', 0, -1);
18
19commit;
20
21select * from products;
22Data Use Case Domains
Another way to validate JSON data is to associate a JSON schema with a JSON column. In 23ai, an extension of the ISO standard Domains is available: Data Use Case Domains.
Consider the following very simple data use case domain that could be considered as a scalar JSON data type alias:
1-- Introducing Data Use Case Domains
2create domain if not exists jsonb as json;
3
4create table test (
5 data jsonb -- JSON alias
6);
7Domains also allow for centralizing JSON schema so that they can be reused across tables and columns. The example below demonstrates how to associate a JSON schema within a data use case domain:
1-- drop table if exists posts purge;
2-- drop domain if exists BlogPost;
3create domain if not exists BlogPost as json
4validate '{
5 "$id": "https://example.com/blog-post.schema.json",
6 "$schema": "https://json-schema.org/draft/2020-12/schema",
7 "description": "A representation of a blog post",
8 "type": "object",
9 "required": ["title", "content", "author"],
10 "properties": {
11 "title": {
12 "type": "string"
13 },
14 "content": {
15 "type": "string"
16 },
17 "publishedDate": {
18 "type": "string",
19 "format": "date-time"
20 },
21 "author": {
22 "$ref": "https://example.com/user-profile.schema.json"
23 },
24 "tags": {
25 "type": "array",
26 "items": {
27 "type": "string"
28 }
29 }
30 },
31 "$def": {
32 "$id": "https://example.com/user-profile.schema.json",
33 "$schema": "https://json-schema.org/draft/2020-12/schema",
34 "description": "A representation of a user profile",
35 "type": "object",
36 "required": ["username", "email"],
37 "properties": {
38 "username": {
39 "type": "string"
40 },
41 "email": {
42 "type": "string",
43 "format": "email"
44 },
45 "fullName": {
46 "type": "string"
47 },
48 "age": {
49 "type": "integer",
50 "minimum": 0
51 },
52 "location": {
53 "type": "string"
54 },
55 "interests": {
56 "type": "array",
57 "items": {
58 "type": "string"
59 }
60 }
61 }
62 }
63}';
64
65-- Now use the Domain as a new column data type!
66create table posts ( content BlogPost );
67
68-- fails
69insert into posts values (json{ 'garbageDocument' : true });
70
71-- works
72insert into posts values (
73 json {
74 'title': 'Best brownies recipe ever!',
75 'content': 'Take chocolate...',
76 'publishedDate': '2024-12-05T13:00:00Z',
77 'author': {
78 'username': 'Bob',
79 'email': 'bob@blogs.com'
80 },
81 'tags': ['Cooking', 'Chocolate', 'Cocooning']
82 }
83);
84
85commit;
86Now let's look closer at the publishedDate field:
1select p.content.publishedDate
2 from posts p;
3
4-- the binary encoded data type is 'string'
5select p.content.publishedDate.type() as type
6 from posts p;
7Results:
| TYPE |
|---|
| string |
Using the type() item method, we can see the date is in fact stored as a string.
Performance Improvement
With data use case domains, the Oracle Database 23ai can not only use JSON schema for JSON data validation but it can also improve performance by leveraging the CAST functionality. Consider the following data use case domain example:
1drop table if exists posts purge;
2
3drop domain if exists BlogPost;
4
5-- Recreate the Domain with CAST/Type coercion enabled
6create domain BlogPost as json
7validate CAST using '{
8 "$id": "https://example.com/blog-post.schema.json",
9 "$schema": "https://json-schema.org/draft/2020-12/schema",
10 "description": "A representation of a blog post",
11 "type": "object",
12 "required": ["title", "content", "author"],
13 "properties": {
14 "title": {
15 "type": "string"
16 },
17 "content": {
18 "type": "string"
19 },
20 "publishedDate": {
21 "extendedType": "timestamp",
22 "format": "date-time"
23 },
24 "author": {
25 "$ref": "https://example.com/user-profile.schema.json"
26 },
27 "tags": {
28 "type": "array",
29 "items": {
30 "type": "string"
31 }
32 }
33 },
34 "$def": {
35 "$id": "https://example.com/user-profile.schema.json",
36 "$schema": "https://json-schema.org/draft/2020-12/schema",
37 "description": "A representation of a user profile",
38 "type": "object",
39 "required": ["username", "email"],
40 "properties": {
41 "username": {
42 "type": "string"
43 },
44 "email": {
45 "type": "string",
46 "format": "email"
47 },
48 "fullName": {
49 "type": "string"
50 },
51 "age": {
52 "type": "integer",
53 "minimum": 0
54 },
55 "location": {
56 "type": "string"
57 },
58 "interests": {
59 "type": "array",
60 "items": {
61 "type": "string"
62 }
63 }
64 }
65 }
66}';
67
68create table posts ( content BlogPost );
69By enabling the JSON schema for type CASTing, we can request the database to use the new extendedType during the binary JSON encoding process. In the example above, this would mean that the encoded type would be a timestamp and no longer a string resulting in less parsing overhead compared to the previous version: from string to timestamp each time we retrieve the field for SQL processing (WHERE clause filtering, SELECT projection, etc.).
Let's check this:
1create table posts ( content BlogPost );
2
3-- We can retrieve the JSON schema associated to the column
4-- via the Data Use Case Domain
5select dbms_json_schema.describe( 'POSTS' );
6
7-- works
8insert into posts values (
9'{
10 "title": "Best brownies recipe ever!",
11 "content": "Take chocolate...",
12 "publishedDate": "2024-12-05T13:00:00Z",
13 "author": {
14 "username": "Bob",
15 "email": "bob@blogs.com"
16 },
17 "tags": ["Cooking", "Chocolate", "Cocooning"]
18 }'
19);
20commit;
21
22-- Now let's look at the publishedDate field...
23select p.content.publishedDate from posts p;
24
25-- ...its binary encoded data type is 'timestamp'
26select p.content.publishedDate.type() from posts p;
27
28-- I can add 5 days to this date...
29select p.content.publishedDate.timestamp() + interval '5' day
30from posts p;
31We use the item method timestamp() in the last statement above because otherwise the SQL dot notation would return a SQL JSON (by default in 23ai) on which we cannot apply an interval operation. However, because the value is already stored as TIMESTAMP inside the binary JSON format, there will be no conversion from JSON to timestamp here.
Last but not least, by enabling type casting, native SQL data type checks are also performed ensuring 100% fidelity between stored binary values in the encoded JSON and SQL data types. As a result, we can store not just the standard JSON data types but also the SQL data types inside the encoded binary JSON such as NUMBER, DATE, TIMESTAMP, TIMESTAMP WITH TIME ZONE, INTERVAL, RAW, VECTOR, etc.
Relational Model Evolution
Our last use case that leverages JSON schema inside the Oracle Database is available since version 12cR2. Imagine, you are a data analyst and the only tool you have to build charts only allows you to see tables and columns. Each time a new data attribute is added, you know that it will take time before you see it appearing inside your BI tool because of the involved development processes.
Now, imagine this is no more the case...
Let's look at the following example:
1create table orders ( j json );
2
3insert into orders(j) values (
4 json { 'firstName': 'Bob', 'address': 'Paris' }
5);
6commit;
7
8select j from orders;
9Results:
| J |
|---|
| { "firstName": "Bob", "address": "Paris" } |
We have an orders table with one column containing a JSON document. The JSON document itself has 2 fields and 2 values. Now, we'll create a JSON Search index (that can perform Full-Text search). This index can optionally maintain a JSON Data Guide in real-time, meaning the JSON schema for the JSON documents stored inside the JSON column.
With this ability comes another one: Change Triggers For Data Guide-Enabled Search Index which, based on the maintained JSON schema, can react to any newly added JSON attributes and dynamically expose these by adding the corresponding virtual columns.
The example below demonstrates this behavior:
1-- drop index s_idx force;
2
3-- Create a Full-Text Search index for JSON with Data Guide
4-- enabled and add_vc stored procedure enabled to change
5-- table structure: add virtual column for JSON fields,
6-- helpful for Analytics => you directly have the existing
7-- JSON fields listed as columns!
8create search index s_idx on orders(j) for json
9parameters('dataguide on change add_vc');
10
11select * from orders;
12Results:
| J | J$address | J$firstName |
|---|---|---|
| { "firstName": "Bob", "address": "Paris" } | Paris | Bob |
1insert into orders(j) values (
2 json { 'firstName': 'Bob', 'address': 'Paris', 'vat': false }
3);
4commit;
5
6select * from orders;
7Results:
| J | J$address | J$firstName | J$vat |
|---|---|---|---|
| { "firstName": "Bob", "address": "Paris" } | Paris | Bob | null |
| { "firstName": "Bob", "address": "Paris", "vat": false } | Paris | Bob | false |
1
2insert into orders(j) values (
3 json { 'firstName': 'Bob', 'address': 'Paris', 'vat': false, 'tableEvolve': true }
4);
5commit;
6
7select * from orders;
8Results:
| J | J$address | J$firstName | J$vat | J$tableEvolve |
|---|---|---|---|---|
| { "firstName": "Bob", "address": "Paris" } | Paris | Bob | null | null |
| { "firstName": "Bob", "address": "Paris", "vat": false } | Paris | Bob | false | null |
| { "firstName": "Bob", "address": "Paris", "vat": false, "tableEvolve": true } | Paris | Bob | false | true |
The trigger executes asynchronously, hence not delaying DML response times, however, because of it being asynchronous, it may take a second before you will see the new virtual column.
Conclusion
We have shown lots of features inside the Oracle Database 23ai which provide powerful capabilities to have JSON data coexist with relational data, and JSON schema clearly strengthens this even more. But this is only the beginning and as you discover more and more features that work the same way regardless of the data model, or that allow going back and forth from one model to another, you'll understand the true value of a converged database which has one goal: removing barriers, simplifying architecture and making developers more productive!
Lean more: